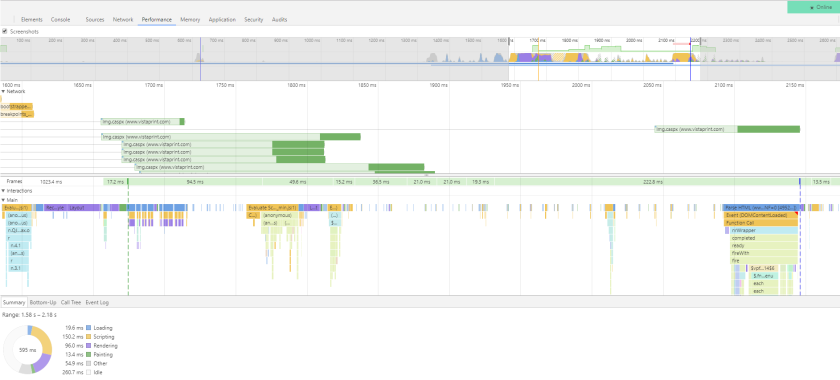
Introduction
Since many companies are moving to a service-based architecture performance testing is more important than ever. There are many tools out there such as JMeter, Gatling, Postman or any of the dozens of applications you can buy. I’m going to focus on Locust for a few reasons:
- It’s free and open source
- It’s quick and easy to get up and running with some basic tests
- Even if you don’t know Python it’s easy to pick up and run with its web-based UI
- It’s scalable – it supports simulating anywhere from one to thousands of users on a single thread
Setup
Getting Locust setup is very straight forward. The most difficult decision is actually deciding which version of Python to use as it supports 2.7, 3.3, 3.4, 3.5, and 3.6. I’m going to go with 3.6 since I already have that installed. If you aren’t sure which version to use I would recommend 3.6 as it’s the latest and is currently under active development. If you’re wondering about the differences between 2.7 and 3.x there’s a good write-up on the Python website. Personally, I don’t like Python’s decision to split the user base but for our purposes here you can use any version.
- The first thing you’ll want to do is download Python
- Second installing Python is as easy as running
pip install locustio. If this doesn’t work verify that Python is in your environmental variables (on Windows) and opening a new command window. If that still doesn’t work following the instructions here should get you started.
- That’s it, you’re ready to go!
Basic Locust Scripting
After installation you’re ready to start scripting. I like to use Visual Studio code but any other editor like Sublime should be just fine.
Here are the basic components of a Locust script:
- Tasks – represent an action to be performed, chosen at random by Locust
- TaskSet – a class that defines the set of tasks to be executed
- HttpLocust – a class that represents the user and is “hatched” to test the system. The behavior of the user is defined by the task_set attribute, which points to a
TaskSetclass.
These are all of the things you need in order to setup a very simple test. More in-depth documentation about the API’s features can be found here.
Here’s a basic script that will hit a webpage and record the response time of the page:
from locust import HttpLocust, TaskSet, task
class UserBehavior(TaskSet):
@task(1)
def profile(self):
self.client.get("/")
class WebsiteUser(HttpLocust):
task_set = UserBehavior
host = "http://google.com"
min_wait = 5000
max_wait = 9000To start the Locust server use the command locust -f (script path/name) and then hit the URL localhost:8089 in your browser to access the UI. From here you can start the script and view the results.
While the script is running you have access to the real-time data via a few different views.
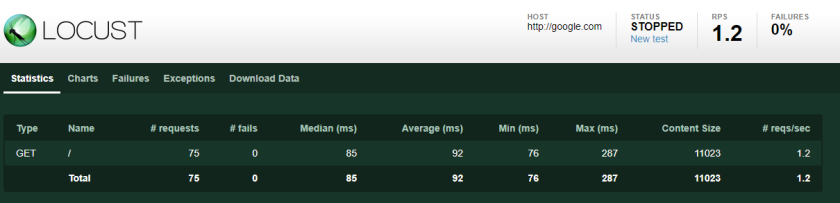
Stats view:
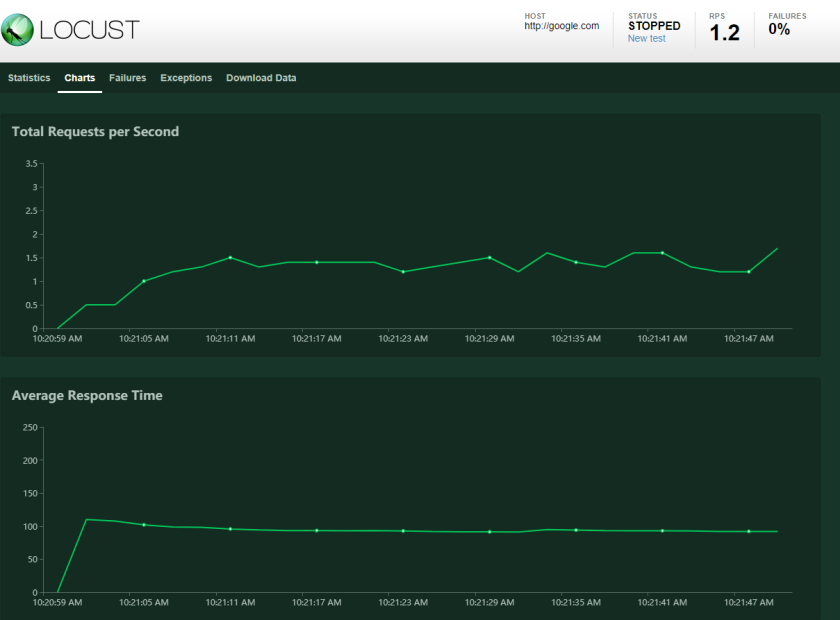
Charts view:
By default the data is not saved to a file, but if you follow the instructions here you can enable that feature. There are a few different ways that you could do this.
Extending the Example
In order to test something useful let’s extend the example to test several pages at one time (we could also test APIs or anything else), output the results to a CSV.
locust -f Example.py --csv=resultFile
Here I’ve added some additional URLs and added a custom response validator for a URL that doesn’t exist (just as an example). You can do plenty of other things in Locust such as validate response data, headers, etc.
from locust import HttpLocust, TaskSet, task
class UserBehavior(TaskSet):
@task(2)
def homepage(self):
self.client.get("/")
@task(1)
def about(self):
self.client.get("/intl/en/about")
@task(1)
def expect404(self):
with self.client.get("/fakeurl", catch_response=True) as response:
if response.content != "Success":
response.success()
class WebsiteUser(HttpLocust):
task_set = UserBehavior
host = "http://google.com"
min_wait = 5000
max_wait = 9000
At this point, assuming you are doing some performance or load testing you can graph your results to find any anomalies. The easiest way to do this is to create a graph in Excel, but there are many other programs than graph data.
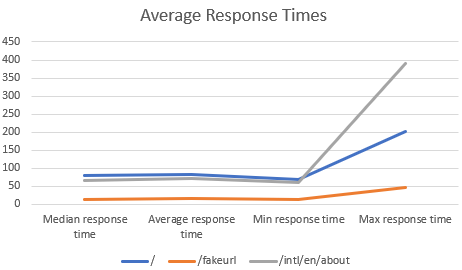
Here we have a graph of the median, average, min and max response times for each URL. Although this extended example is still simple it can be expanded to test nearly anything related to web requests. Locust itself is simple, powerful and easily extendable which is why I like it.